Hello World
My name is Ben Porter. I write code and make games.
You can follow me on Twitter and Mastodon.
Some of my projects are presented below and a list is here.
Call of Duty
Windows Xbox Playstation


I’m currently working on the Call of Duty franchise at Sledgehammer Games as a Feature Lead in UI Engineering. [Vanguard, Modern Warfare II, Modern Warfare III]
MoonQuest
Windows macOS Linux C++ OpenGL SFML




There’s an inviting strangeness to it…
PC Gamer
A procedurally-generated adventure game with wild forests, giant mountains and ancient ruins. The custom engine features destructible terrain, randomised worlds, path-finding AI, fluid simulation, and much more. Funded in part by Film Victoria and Kickstarter. [Steam]
Fugu
Windows C++ Lua Qt OpenGL

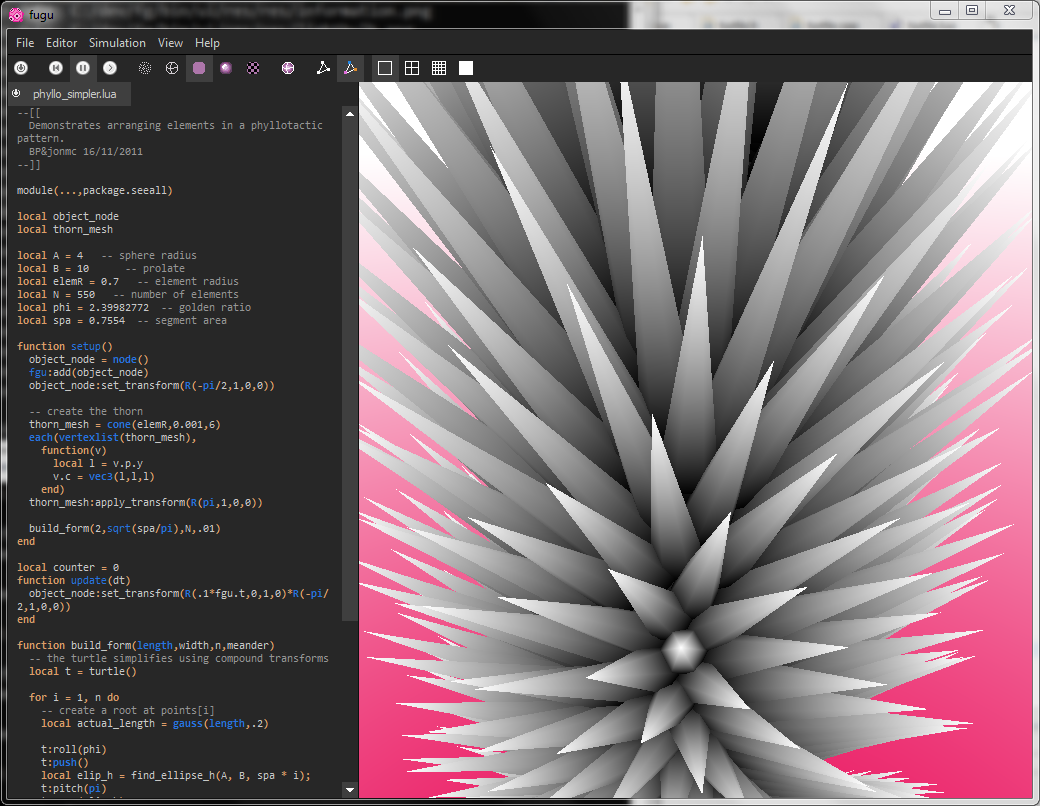
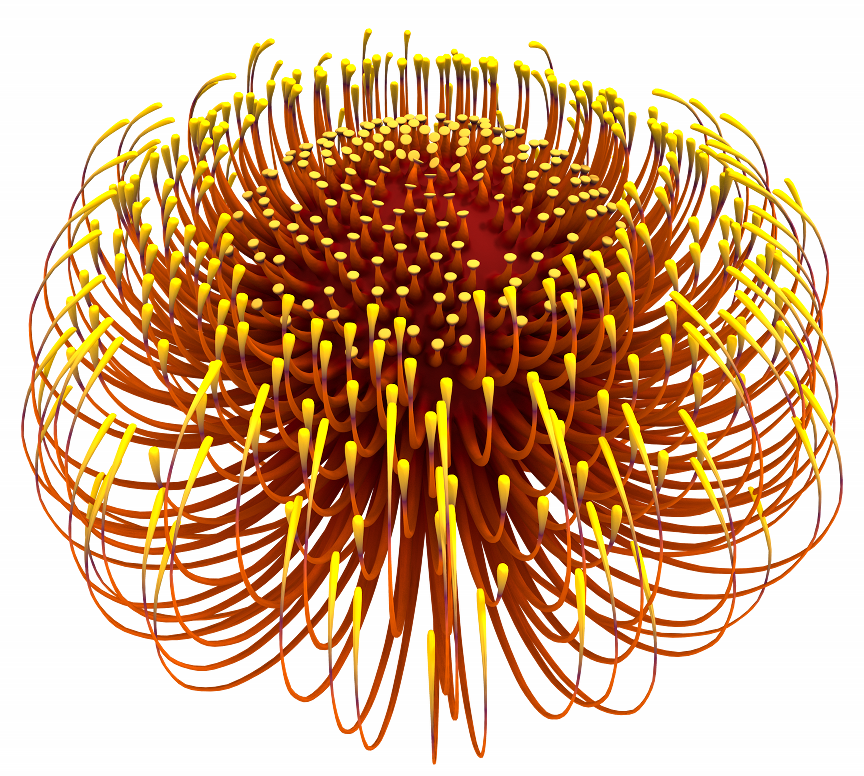
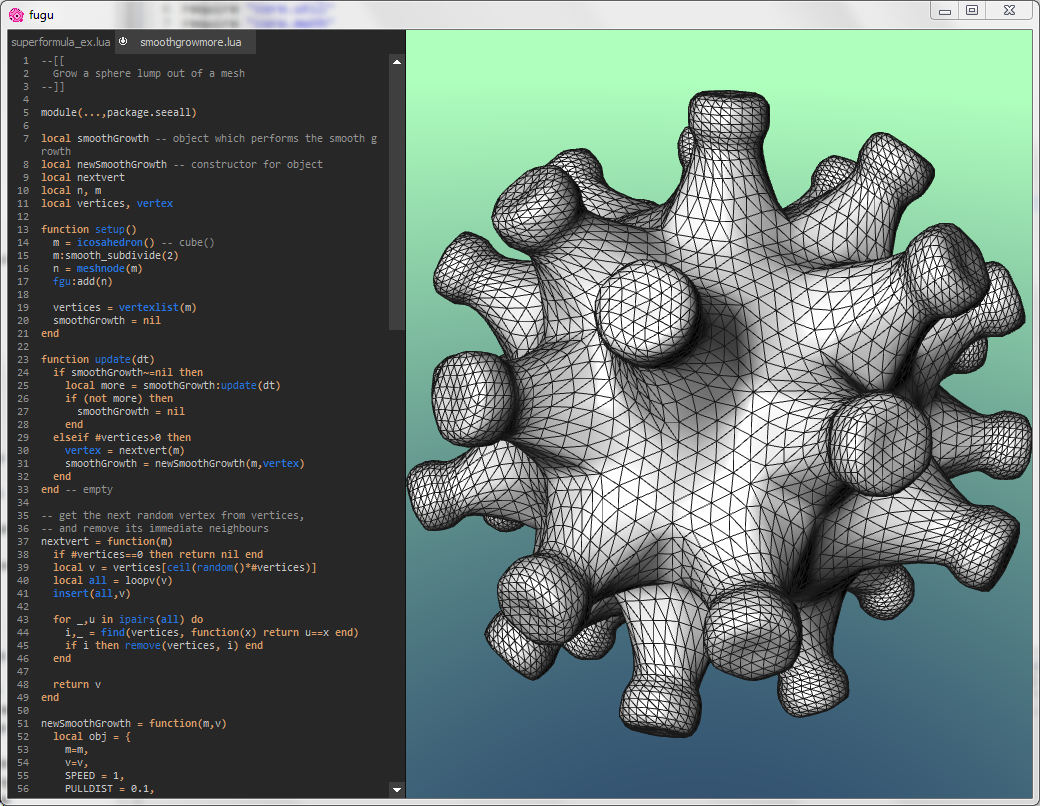
A procedural modelling system for rapid exploration of organic 3D forms. Built using Qt and supports interactive scripting via Lua. [Site, Technical Paper, Example Video]
Hello Vulkan
C++ Vulkan

An example application that initialises and displays a 3D model using the Vulkan API. The code is heavily based on this Vulkan tutorial. The lighthouse model is courtesy of Sam Cotman. [Github]
No Mario’s Sky
Windows Unity
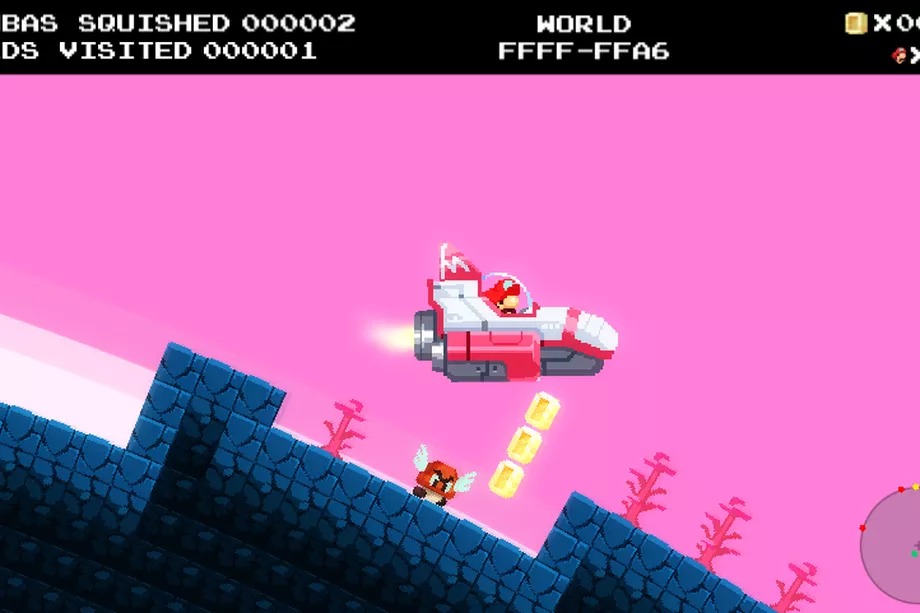
Mario meets No Man’s Sky in this fiendishly fun fan-made game.
Wired UK
A procedurally-generated exploration game made in 72 hours for Ludum Dare. It had over 200,000 downloads and was featured in several games sites, but was taken down by a Nintendo DMCA request. You can still download a modified version which we titled DMCA’s Sky. [Download]
Generative Modelling
C++

I have a PhD in Computer Science from Monash University. My research produced a novel method for generating complex organic 3D meshes. I was awarded the Mollie Holman medal for my dissertation. [Read More, Computer & Graphics Article, Academic Publications]
Shade Dogs
iOS Objective C Cocos2D



A colourful puzzler for iOS developed in collaboration with Jakob Haglof. One interesting feature of this project is that the levels were constructed within After Effects and exported using a custom pipeline I built. [Trailer]
Pixel Dailies
Pixel Art




In 2014 I founded Pixel Dailies, a community of pixel artists that has now grown to have over 50,000 followers and hundreds of daily contributions. My personal pixel art has also been featured in Edge Magazine’s “The Art of The Pixel”. [Pixel Dailies]